Hierarchical Clustering¶
This module implements various hierarchical clustering algorithms. The clustering technique groups similar data points into groups called clusters. Similarity can be measured by multiple methods, such as Pearson’s correlation, Spearman rank correlation, Euclidean distance, etc.
Hierarchical clustering is a technique that arranges a set of nested clusters as a tree. It can be agglomerative or divisive. Agglomerative hierarchical clustering merges smaller and similar clusters to form bigger clusters in multiple iterations. A dendrogram is a common technique to visualize the nested clusters. Divisive hierarchical clustering is the opposite concept. At each iteration, bigger clusters are separated into smaller and dissimilar clusters. Hierarchical clustering is useful to discern similar properties in datasets.
Note
Underlying Literature
The following sources describe this method in more detail:
TF 2.0 DCGAN for 100x100 financial correlation matrices by Gautier Marti.
Implementation¶
This module creates optimal leaf hierarchical clustering as shown in Marti, G. (2020) TF 2.0 DCGAN for 100x100 financial correlation matrices by arranging a matrix with hierarchical clustering by maximizing the sum of the similarities between adjacent leaves.

Example¶
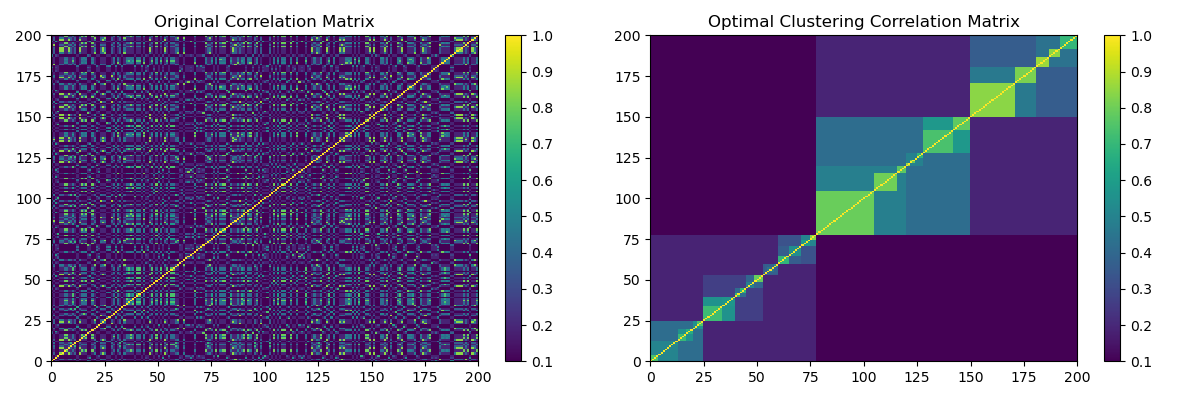
(Left) HCBM matrix. (Right) Optimal Clustering of the HCBM matrix found by the function optimal_hierarchical_cluster.¶
