Clustered MDA and MDI¶
In the book Machine Learning for Asset Managers, as an approach to deal with substitution effects, Clustered Feature Importance was introduced. It clusters similar features and applies feature importance analysis (like MDA and MDI) at the cluster level. The value add of clustering is that the clusters are mutually dissimilar and hence reduces the substitution effects.
It can be implemented in two steps as described in the book:
Features Clustering: As a first step we need to generate the clusters or subsets of features we want to analyse with feature importance methods. This can be done using the feature cluster module. It implement the method of generating feature clusters as in the book.
Clustered Importance: Now that we have identified the number and composition of the clusters of features. We can use this information to apply MDI and MDA on groups of similar features, rather than on individual features. Clustered Feature Importance can be implemented by simply passing the feature clusters obtained in Step-1 to the clustered_subsets argument of the MDI or MDA feature importance algorithm.
How Cluster Feature Importance can be applied:
Clustered MDI (code Snippet 6.4 page 86 ): We compute the clustered MDI as the sum of the MDI values of the features that constitute that cluster. If there is one feature per cluster, then MDI and clustered MDI are the same.
Clustered MDA (code Snippet 6.5 page 87 ): As an extension to normal MDA to tackle multi-collinearity and (linear or non-linear) substitution effect. Its implementation was also discussed by Dr. Marcos Lopez de Prado in the Clustered Feature Importance (Presentation Slides).
Note
The implementation of Clustered feature importance is included in the functions for MDI and MDA.
Example¶

The following are the resulting images from the Clustered MDI & Clustered MDA feature importances respectively:
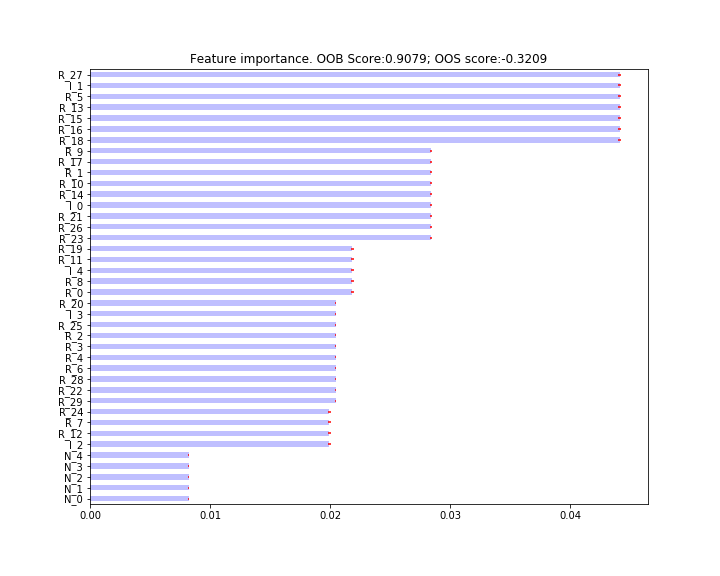
Clustered MDI¶
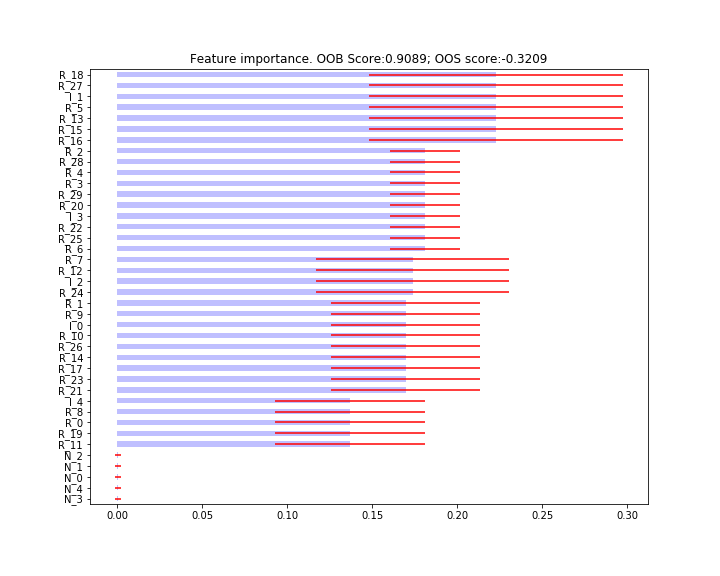
Clustered MDA¶
Research Notebook¶
The following research notebooks can be used to better understand the Clustered Feature Importance and its implementations.

Presentation Slides¶


Note
These slides are a collection of lectures so you need to do a bit of scrolling to find the correct sections.
pg 19-29: Feature Importance + Clustered Feature Importance.
pg 109: Feature Importance Analysis
pg 131: Feature Selection
pg 141-173: Clustered Feature Importance
pg 176-198: Shapley Values