MDI, MDA, and SFI¶
“Backtesting is not a research tool. Feature importance is.” (Lopez de Prado)
Note
Underlying Literature
The following sources describe this method in more detail:
Advances in Financial Machine Learning, Chapter 8 by Marcos Lopez de Prado.
3 Algorithms for Feature Importance¶
The book describes three methods to get importance scores:
Mean Decrease Impurity (MDI): This score can be obtained from tree-based classifiers and corresponds to sklearn’s feature_importances attribute. MDI uses in-sample (IS) performance to estimate feature importance.
Mean Decrease Accuracy (MDA): This method can be applied to any classifier, not only tree based. MDA uses out-of-sample (OOS) performance in order to estimate feature importance.
Single Feature Importance (SFI): MDA and MDI feature suffer from substitution effects. If two features are highly correlated, one of them will be considered as important while the other one will be redundant. SFI is a OOS feature importance estimator which doesn’t suffer from substitution effects because it estimates each feature importance separately.


Example¶
An example showing how to use various feature importance functions:

The following are the resulting images from the MDI, MDA, and SFI feature importances respectively:
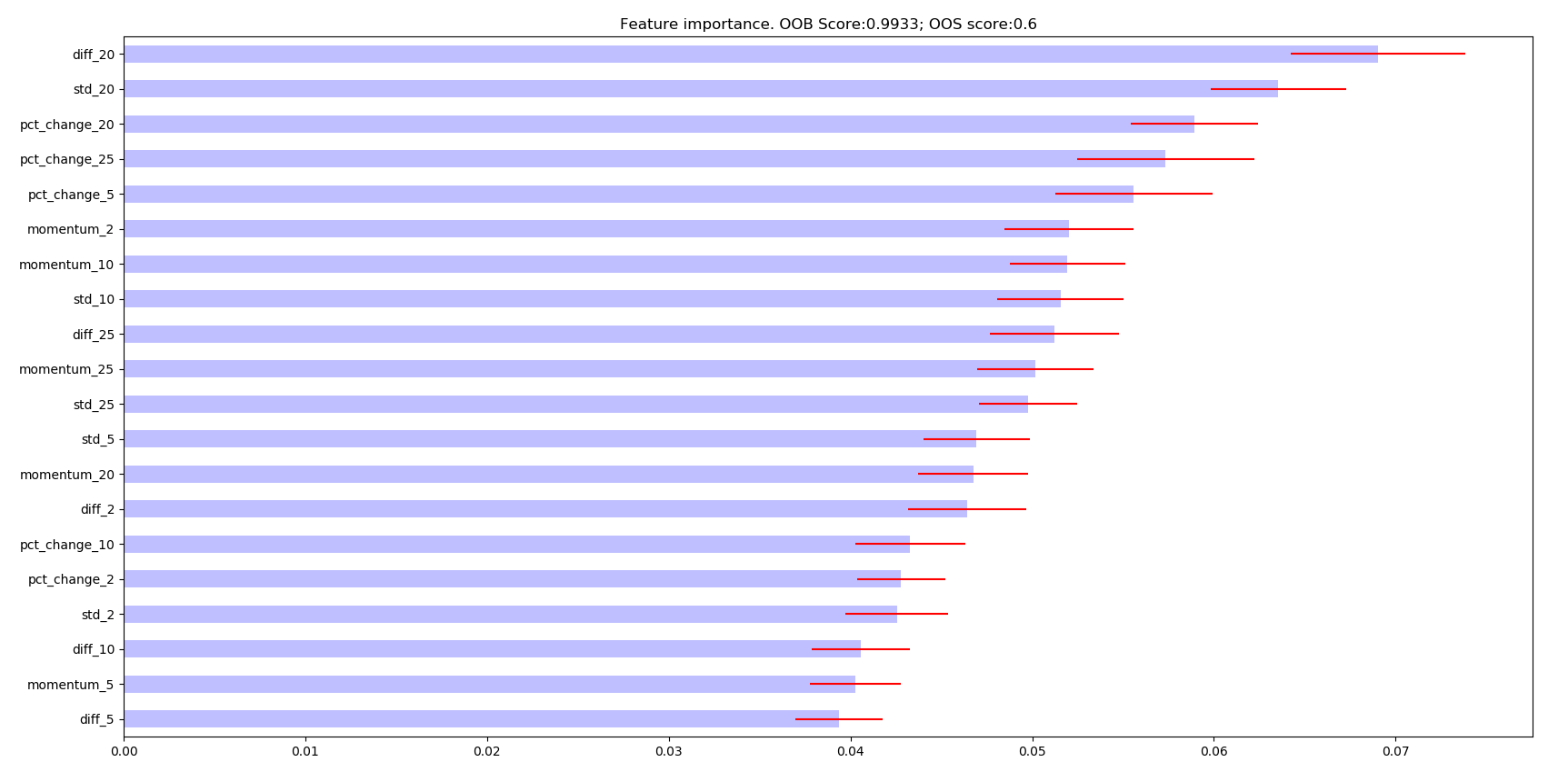
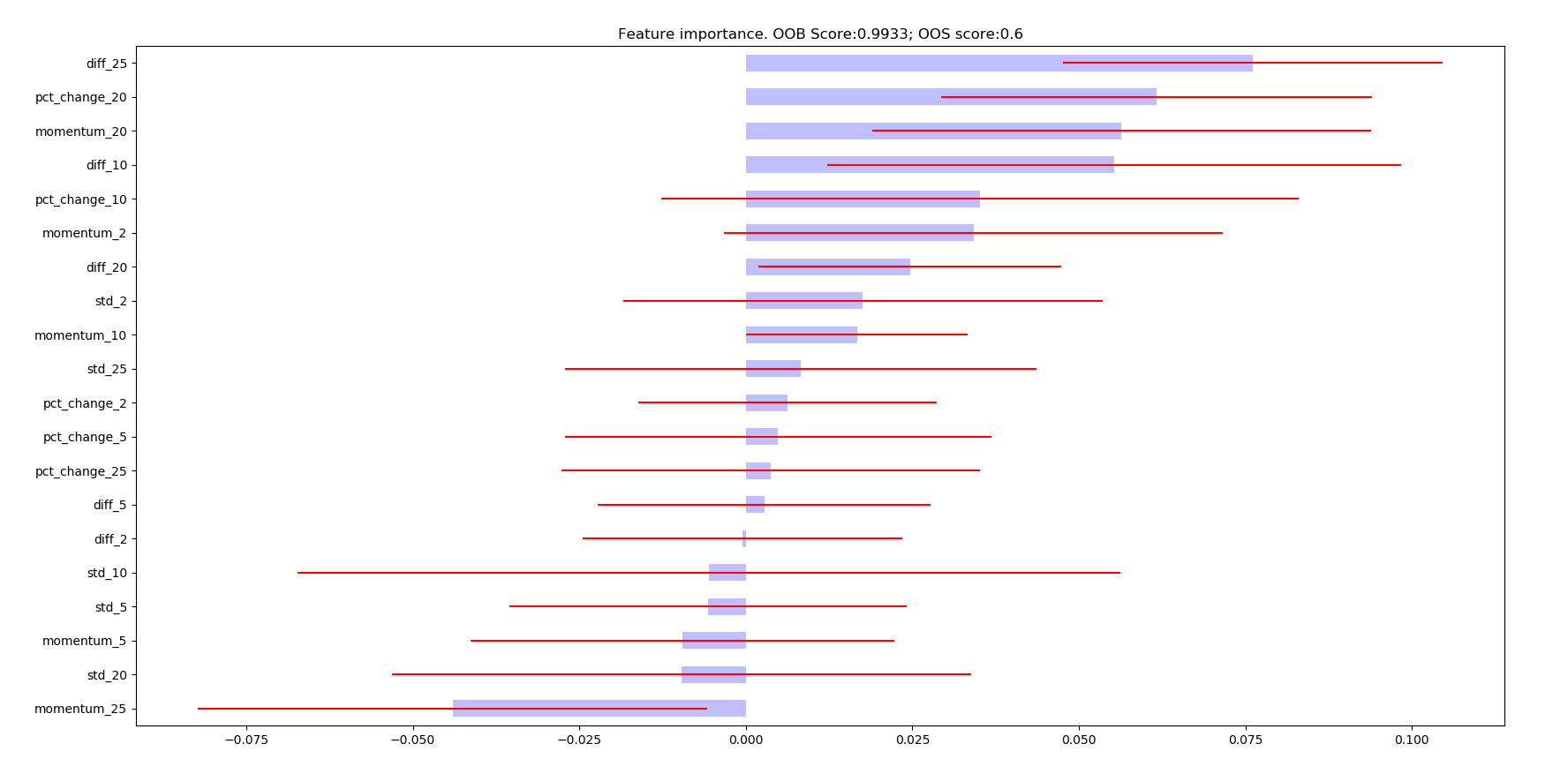
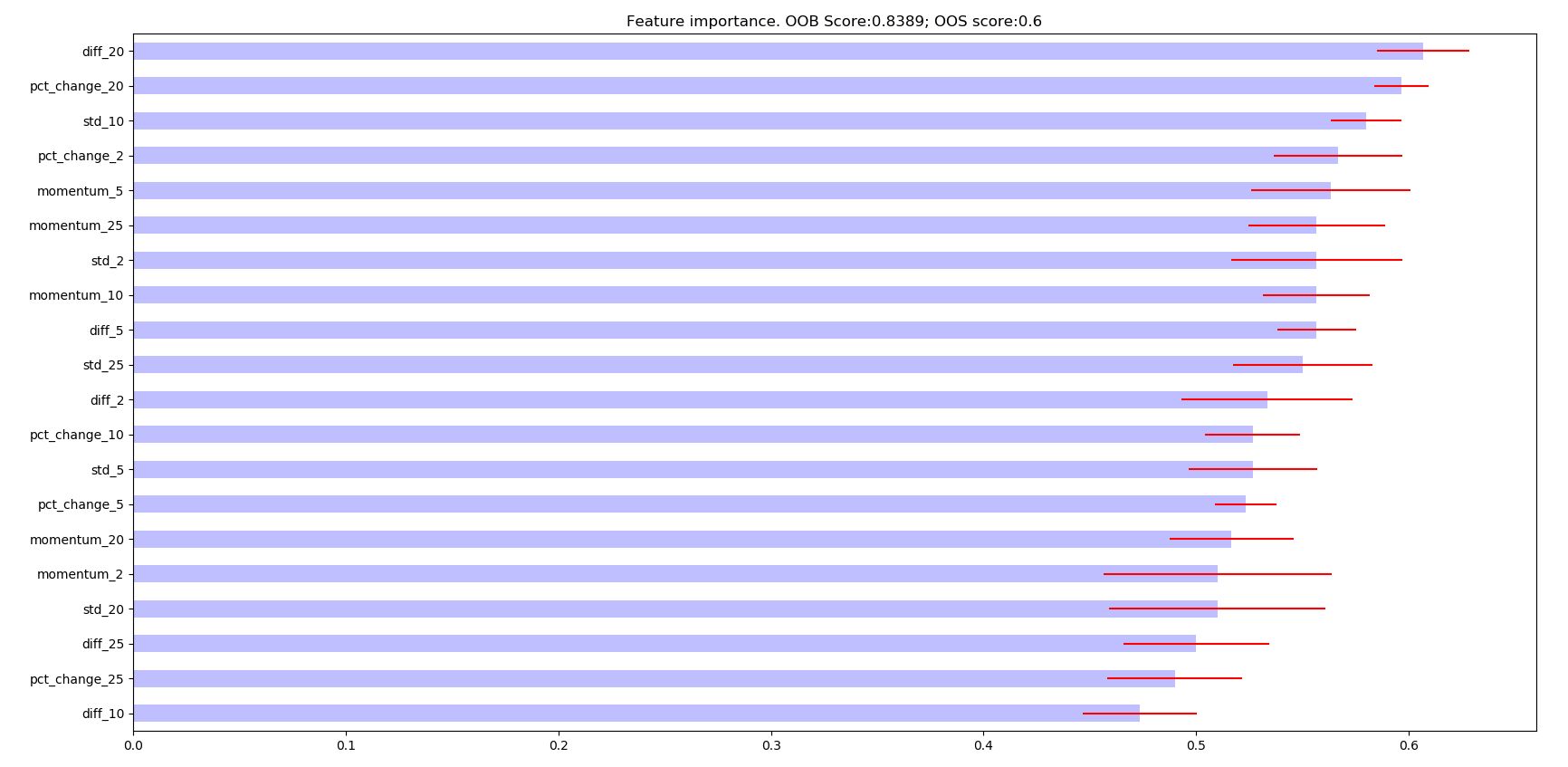
Research Notebook¶

Presentation Slides¶

Note
These slides are a collection of lectures so you need to do a bit of scrolling to find the correct sections.
pg 19-29: Feature Importance + Clustered Feature Importance.
pg 109: Feature Importance Analysis
pg 131: Feature Selection
pg 141-173: Clustered Feature Importance
pg 176-198: Shapley Values