Optimal Number of Clusters (ONC)¶
The ONC algorithm detects the optimal number of K-Means clusters using a correlation matrix as input.
Clustering is a process of grouping a set of elements where elements within a group (cluster) are more similar than elements from different groups. A popular clustering algorithm is the K-means algorithm that guarantees the convergence in a finite number of steps.
The K-means algorithm has two caveats. It requires the user to set the number of clusters in advance and the initialization of clusters is random. Consequently, the effectiveness of the algorithm is random. The ONC algorithm proposed by Marcos Lopez de Prado addresses these two issues.
Note
Underlying Literature
The following sources elaborate extensively on the topic:
Detection of false investment strategies using unsupervised learning methods by Marcos Lopez de Prado and Lewis, M.J. Describes the ONC algorithm in detail. The code in this module is based on the code written by the researchers.
Machine Learning for Asset Managers by Marcos Lopez de Prado. Features additional descriptions of the algorithm and includes exercises to understand the topic in more detail.
Clustering (Presentation Slides) by Marcos Lopez de Prado and Lewis, M.J. Briefly describes the logic behind the ONC algorithm.
Codependence (Presentation Slides) by Marcos Lopez de Prado and Lewis, M.J. Explains why the angular distance metric is used to get distances between elements.
Based on the Detection of false investment strategies using unsupervised learning methods paper, this is how the distances and scores are calculated:
Distances between the elements in the ONC algorithm are calculated using the same angular distance used in the HRP algorithm:
where \(\rho_{i,j}\) is the correlation between elements \(i\) and \(j\) .
Distances between distances in the clustering algorithm are calculated as:
Silhouette scores are calculated as:
where \(a_i\) the average distance between element \(i\) and all other components in the same cluster, and \(b_i\) is the smallest average distance between \(i\) and all the nodes in any other cluster.
The measure of clustering quality \(q\) or \(t-score\):
where \(E[\{S_i\}]\) is the mean of the silhouette scores for each cluster, and \(V[\{S_i\}]\) is the variance of the silhouette scores for each cluster.
The ONC algorithm structure is described in the work Detection of false investment strategies using unsupervised learning methods using the following diagrams:
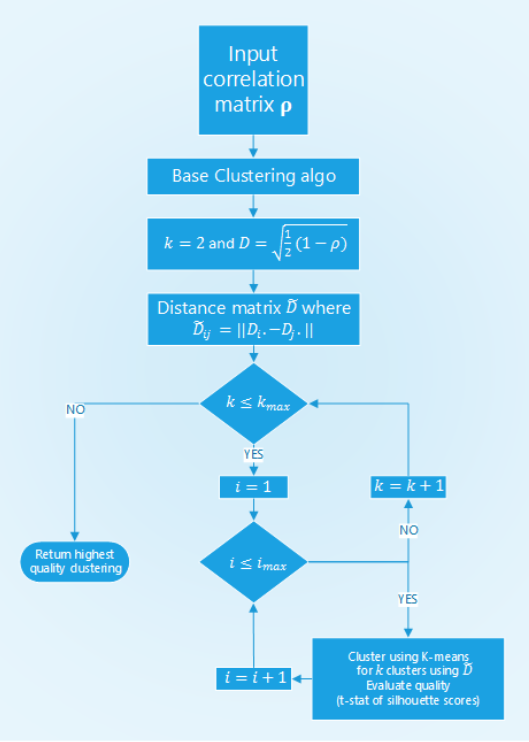
Structure of ONC’s base clustering stage.¶
In the base clustering stage first, the distances between the elements are calculated, then the algorithm iterates through a set of possible number of clusters \(N\) times to find the best clustering from \(N\) runs of K-means for every possible number of clusters. For each iteration, a clustering result is evaluated using the t-statistic of the silhouette scores.
The clustering result with the best t-statistic is picked, the correlation matrix is reordered so that clustered elements are positioned close to each other.
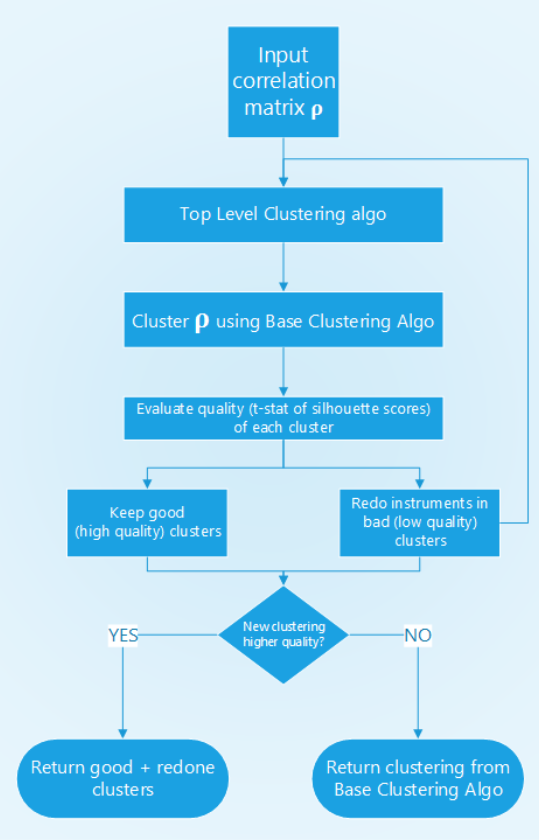
Structure of ONC’s higher-level stage.¶
On a higher level, the average t-score of the clusters from the base clustering stage is calculated. If more than two clusters have a t-score below average, these clusters go through the base clustering stage again. This process is recursively repeated.
Then, based on the t-statistic of the old and new clusterings it is checked whether the new clustering is better than the original one. If not, the old clustering is kept, otherwise, the new one is taken.
The output of the algorithm is the reordered correlation matrix, clustering result, and silhouette scores.
Implementation¶


Presentation Slides¶
